
LLM Seeding: Den komplette guide til at få AI-søgninger til at citere dit brand (2026)
AI-referred besøgende konverterer med op til 18 %, omtrent 4–10 gange højere end organisk søgning. Alligevel udgør AI-citations stadig under 2 % af den samlede webtrafik. De brands, der mestrer LLM seeding nu, opbygger en selvforstærkende autoritet, før kanalen mættes. Denne guide fortæller dig præcis hvordan.
Din konkurrent optræder netop nu i et ChatGPT-svar. Det gør du ikke. Det er ikke tilfældigt, og det er ikke held. Det er resultatet af en bevidst strategi kaldet LLM seeding: den praksis at bearbejde dit brands tilstedeværelse på tværs af nettet, så large language models citerer dig, når brugerne stiller de spørgsmål, der er vigtige for din forretning.
LLM seeding er en specifik del af din overordnede Answer Engine Optimization-strategi. Indsatsen skifter hurtigt. LLMs citerer kun 2–7 domæner pr. svar sammenlignet med Googles klassiske 10 blå links. Konkurrencen om disse pladser intensiveres, og når en model har etableret en betroet kilde, har den tendens til at forstærke dette valg på tværs af relaterede forespørgsler. Det er winner-takes-most-dynamik, indlejret i modellernes parametre.
Hvis du ikke er med i disse svar i dag, oplærer du brugerne til at forbinde din kategori med et andet brands navn.
Denne guide dækker det hele: hvordan AI-modeller faktisk beslutter, hvad de citerer, de strategier der konsekvent giver mentions, de platforme der vejer tungest, og hvordan du måler, om noget af det overhovedet virker.
Hvad er LLM Seeding?
LLM seeding, en del af den overordnede Answer Engine Optimization (AEO)-strategi, er den praksis strategisk at distribuere præcist, autoritativt og maskinlæsbart content på tværs af nettet, så AI-modeller som ChatGPT, Claude, Perplexity og Google AI Overviews inkorporerer dit brand i deres genererede svar.
Begrebet kan opdeles simpelt:
LLM (Large Language Model): Den AI-teknologi bag AI search værktøjer som ChatGPT, Claude, Perplexity og Gemini.
Seeding: At plante din brandinformation i det jdata, hvor AI dyrker sine svar; træningsdata, diverse webkilder og autoritative platforme.
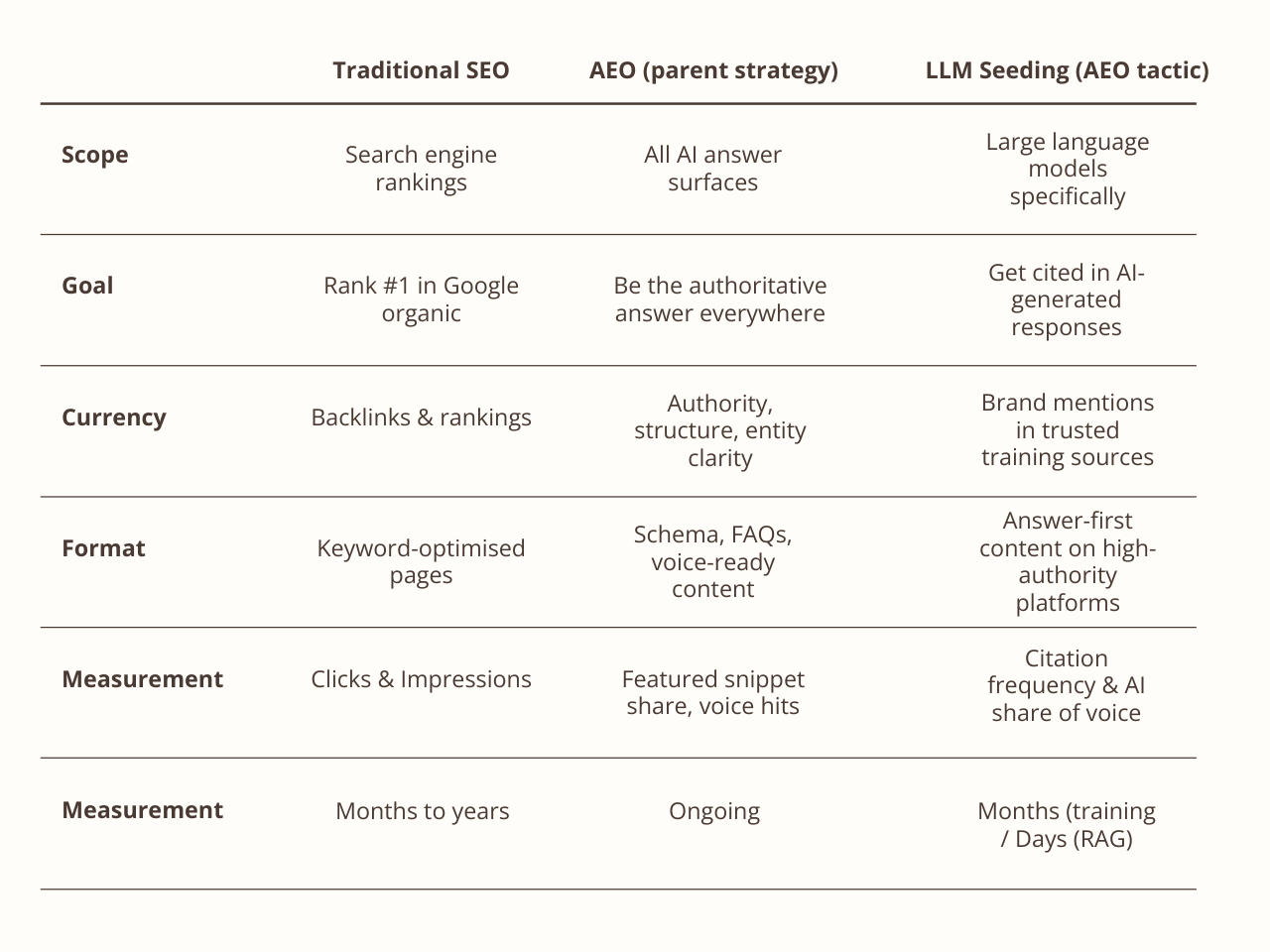
Traditionel SEO: Hvordan ranker jeg på første side? LLM seeding: Hvordan bliver jeg den kilde, en AI stoler nok på til at citere? Det er helt forskellige spørgsmål med helt forskellige svar. Nedenstående tabel giver et overordnet billede af forskellene:
Hvordan LLM's faktisk opdager og citerer dit brand
For at forstå, hvorfor AI-assistenter citerer bestemte brands, er det nødvendigt at forstå de to grundlæggende forskellige måder, LLM's tilgår information på.
Parametrisk viden (Træningsdata)
Det er alt det, modellen har "bagt ind" under træning: et enormt crawl af nettet, bøger, Wikipedia, Reddit og utallige andre kilder. Cirka 22 % af de store AI-modellers træningsdata stammer fra Wikipedia alene. Denne viden er statisk, fastlåst ved træningens afslutning og tilgås på millisekunder uden nogen ekstern forespørgsel. Entiteter, der nævnes hyppigt på tværs af autoritative kilder under træning, udvikler stærkere neurale "repræsentationer", og dermed en langt større sandsynlighed for at dukke op i svar. Omkring 60 % af ChatGPT-forespørgsler besvares udelukkende fra denne parametriske hukommelse, uden at nogen live web-søgning overhovedet foretages.
Hvad det betyder for dig: Hvis dit brand, produkt eller din ekspertise ikke er vævet ind på tværs af flere troværdige kilder inden en models træningsskæringsdato, er du reelt usynlig for flertallet af forespørgsler, som den model nogensinde vil besvare.
Hentet viden (RAG, Retrieval-Augmented Generation)
De resterende 40 % af gangene henter LLM's aktivt realtidsinformation. Brugerens forespørgsel konverteres til vector embeddings, relevante dokumenter hentes og rangordnes igen, og modellen syntetiserer et svar fra disse kilder. Sådan fungerer redskaber som Perplexity, Google AI Overviews og ChatGPT Search, når de browser nettet i realtid.
Hvad det betyder for dig: For realtidshentning er aktualitet, crawlbarhed, strukturerede data og domæneautoritet enormt vigtige. En velstruktureret side på et domæne med høj domæneautoritet, relevant indhold, og publiceret for en måned siden, kan overgå et tre år gammelt indlæg, selv fra et større brand, og brugt i modellens træningsdata.
De tre ting, der driver AI-citations
På tværs af begge tilgange adskiller tre faktorer konsekvent citerede brands fra usynlige:
Konsistens. Din brand information fremtræder med de samme præcise detaljer på tværs af mange troværdige kilder. Modstridende eller sparsom information oplærer modeller til at være usikre. Og usikre modeller undgår at citere.
Struktur. Content anvender klare overskrifter, definerede begreber, FAQ-formater, schema markup og lister, som AI kan analysere uden tvetydighed. Forskning viser, at 44,2 % af alle LLM-citations stammer fra de første 30 % af en artikel, dvs. indledningen. Begynd med svar.
Autoritet. Tredjeparts mentions, anmeldelser, Wikipedia-tilstedeværelse og citations fra etablerede publikationer signalerer troværdighed. Brand-søgevolumen, ikke backlinks, er den stærkeste forudisgelse for AI-citations, med en korrelation på 0,334, højere end korrelationen på 0,255 mellem referring domains og organiske placeringer.
Hvorfor tallene kræver din opmærksomhed nu
LLM seeding er ikke hype. Det haster med at få dit brand placeret.
Trafikken er forsat begrænset, men eksplosiv. AI-referred trafik udgør i dag under 2 % af den samlede webtrafik. Men AI-baseret søgetrafik voksede 527 % år-over-år mellem januar og maj 2025. Ifølge Semrush forventes AI-søgetrafik at overstige traditionel søgning inden udgangen af 2027. Medregner man AI Overviews, er tallet for webtrafik dog langt højere, da Google bruger AI Overviews i mere end halvdelen af sine svar. Det er desuden sandsynligt, at det samlede antal søgninger er steget markant. Mange søgninger foretages på LLM's og resulterer aldrig i et klik videre til et brands website.
Webtrafik kvaliteten fra AI-søgninger er ekstraordinær. Forskning, der analyserede 1.200+ publisher-sites, viste, at LLM-referred besøgende konverterede til tilmeldinger med 1,66 %, sammenlignet med blot 0,15 % fra traditionel søgning. En anden undersøgelse viste, at AI-drevne besøgende konverterer 4,4 gange hurtigere end besøgende fra organisk søgning. Hvorfor? Fordi når en LLM citerer dig, er brugeren allerede gået gennem en del af funnel. AI'en har sammenlignet dig med alternativer, fundet dig troværdig og præsenteret dig som svaret. Webbesøgende kommer med langt mere viden og en form for forhånds kvalifikation. Sagt på en anden måde; en stor del af trafikken vil være high-intent, hvorfor det også er ekstremt vigtigt at jeres website matcher dette.
Zero-click. En ny verden. 60 % af søgninger ender nu uden noget klik videre til brands hjemmesiden. Men selv når brugerne aldrig besøger dit site, opbygger det at blive nævnt i et AI-svar brand-kendskab og driver direkte søgninger senere. Korrelationen mellem AI-chatbot-mentions og brand-søgevolumen er 0,334. Højere end link-til-rangering-korrelationen, som SEO har baseret sig på i to årtier.
Spillebanen udjævnes. Næsten 90 % af ChatGPT-citations stammer fra sider, der rangerer på position 21 eller lavere i Google. LLMS belønner altså ikke nødvendigvis de samme brands, der dominerer traditionel søgning. En velstruktureret artikel på side 4 i Google kan overgå en konkurrents toprangerede side, hvis den giver bedre og mere strukturerede svar til ChatGPT.
Vinduet for at vinde i AI-search er åbent, men det lukker sig. Kun 16 % af brands måler systematisk AI-søgeperformance pr ultimo 2025. Størstedelen af jeres konkurrenter optimerer i blinde. Eller optimerer slet ikke. Det er jeres mulighed.
LLM Seeding Strategy Framework
Trin 1: Kortlæg dine prompts, inden du skriver et ord
Inden du producerer noget content, skal du forstå, hvordan dine kunder søger i LLM's. Ikke hvordan de søger på Google. AI-søgninger er samtalepræget, kontekstuelle og specifikke: "Hvad er det bedste GDPR-kompatible lønsystem til en europæisk startup med 50 medarbejdere?" er en AI-søgning, "lønsoftware Europa" er en Google-søgning.
Det er vigtigt at afspejle den samtaleprægede natur fra LLM's, når besøgende lander på jeres website. Derfor er det afgørende at aktivere chat på dit website for at fortsætte den samtalemæssige kontekst.
Byg et prompt map: oplist ethvert spørgsmål som en potentiel kunde måske stiller en AI-assistent på hvert trin i deres kunderejse, awareness, consideration, decision og post-purchase. Tænk i brugerintention, ikke blot søgeord. Målet er at forstå, hvilke samtaler dit brand naturligt bør indgå i. Forespørg manuelt ChatGPT, Le Chat (Mistral), Perplexity og Claude med branchespecifikke spørgsmål, og studér mønstrene i, hvem der citeres og hvordan.
Trin 2: Publicér autoritativt, troværdigt, svar-først content
Det vigtigste content-princip for LLM seeding: led med svaret, og forklar det derefter. AI-modeller favoriserer stærkt content, hvor konklusionen fremgår i første afsnit. Underbyg den derefter med specifikke detaljer: statistikker, sammenligninger, navngivne eksempler og ekspertperspektiv.
En central taktik her er semantic chunking: at organisere dit content i korte, klart mærkerede sektioner, der hver fokuserer på én enkelt idé eller et svar. Chunked content med overskrifter er langt lettere for AI at analysere, vurdere og citere. Brug en ensartet layout for hvert afsnit. En gentagelig struktur signalerer troværdighed og gør dit content forudsigeligt nok til, at AI kan støtte sig til det.
Strukturér hvert stykke med:
- Et direkte svar på det primære spørgsmål i det indledende afsnit
- Klare H2/H3-overskrifter, der afspejler, hvordan en bruger måske formulerer spørgsmålet
- Korte, semantisk selvstændige sektioner (semantic chunking)
- Specifikke, verificerbare fakta (datoer, procentsatser, firmanavne, studiekilder)
- Et TL;DR eller key takeaway-sammendrag. Modeller benytter konsekvent disse
- FAQs der matcher den samtaleprægede kontekst fra rigtige AI-prompts
Undgå vagt, forsigtigt sprog. AI-modeller behandler dit content som en meget bogstavelig læser. "Brancheledende løsninger, der transformerer forretningsresultater" giver intet udtrækkeligt. "Redskabet reducerer kundesvartiden med 40 % på under 30 dage, baseret på data fra 200 implementeringer" gør derimod.
Trin 3: Byg et netværk af tredjeparts-mentions
Dit eget website er én stemme. AI opbygger tillid fra et kor af kilder. Målet er konsistent, præcis brandinformation spredt ud over mange troværdige, uafhængige kilder.
PR og medie-outreach: Et enkelt mention på en respekteret branchepublikation vejer mere i citations end et dusin indlæg på din egen blog. Brands i top 25 % for web-mentions får 10 gange mere AI-synlighed end andre. Søg bidragsartikler, ekspertcitater og produktomtaler i fagmedier. Redskaber som HARO (nu Connectively) eller Featured.com kan hjælpe dig med at finde journalistforespørgsler at bidrage til.
Wikipedia: Da cirka 22 % af store AI-modellers træningsdata stammer fra Wikipedia, er en neutral, Wikipedia-tilstedeværelse et af de bedste muligheder, som er tilgængelige for etablerede brands. Følg Wikipedias redaktionelle standarder nøje. Ethvert tegn på reklamepræget content vil resultere i sletning og kan skade dit brands opfattede troværdighed hos Large Language Models.
Strukturerede anmeldelser: Anmeldelser på G2, Capterra, Trustpilot og Google Business Profile skaber bruger-genereret content, som AI henter fra. Specificitet er enormt vigtig her. En anmeldelse, der siger "Reducerede vores supporthenvendelsesvolumen med 35 % i første kvartal," er citations-værdig. "Fantastisk produkt, kan varmt anbefales" er støj. Spørg dine bedste kunder om anmeldelser og inkluder specifikke spørgsmål, der sigter mod svar med data inkluderet: "Hvilket problem løste dette, og hvilket målbart resultat opnåede I?"
Trin 4: Oprethold semantisk konsistens på tværs af alle kanaler
Dette trin overses ofte, men er meget vigtigt. LLM's opbygger associationer mellem brands og emner baseret på mønstre i data. Hvis din messaging er bred, skiftende eller inkonsistent på tværs af kanaler, f.eks. forskellig positionering på jeres blog versus din LinkedIn versus dine pressemeddelelser, så risikerer I at disse mønstre bliver svage eller modstridende, og det semantiske link mellem jeres brand og jeres kerneemne derved svækkes.
Vælg dine tre til fem vigtigste tematiske associationer, de emner, du mest ønsker at eje i AI-svar, og forstærk dem konsekvent overalt: på dit site, i dine artikler, i community-indlæg, i PR-citater og i dit sociale content. Jo mere konsekvent du optræder i de samme kontekster med den samme framing, jo stærkere og mere pålidelig bliver dit brands repræsentation i træningsdata.
Trin 5: Gør krav på og optimér din Knowledge Graph-tilstedeværelse
AI-modeller har et begreb om "entitet"; en distinkt, genkendelig ting i verden. Stærke brands har stærke entitetsrepræsentationer: konsistent navn, konsistente attributter, konsistente associationer på tværs af dusinvis af kilder. Svage entiteter er tvetydige, modstridende eller sparsomt repræsenterede.
For at styrke dit brands entitet:
- Sørg for, at din Google Business Profile er komplet, præcis og regelmæssigt opdateret
- Oprethold konsistent NAP-information (Name, Address, Phone) på tværs af alle platforme
- Brug struktureret data markup til formelt at definere dit brands attributter
- Byg forbindelser mellem dit content og etablerede entiteter (branchetermer, anerkendte redskaber, navngivne frameworks), så AI kan kontekstualisere dit brand inden for sin eksisterende vidensbase
Trin 6: Publicér proprietære data og dybdegående indhold
En af de mest effektive LLM seeding-taktikker er at eje et unikt datapunkt, som få eller ingen andre kan replikere. Når en LLM opdager et unikt faktum, vender den tilbage til den kilde gentagne gange, fordi ingen alternativ kilde kan imødekomme den samme forespørgsel.
Gennemfør mini-undersøgelser, analysér jeres egne kundedata, eller bestil tredjeparts-analyser. Præsentér fund med så meget korrekt attribution som muligt dato, metode, stikprøvestørrelse. Det signalerer til AI, at dataene er verificerbare og citerbare. De to ting, den har brug for, inden den inkluderer en påstand i et svar.
De bedste platforme til LLM Seeding
Ikke alle content-kanaler når AI-modellerne i samme grad. Prioritér ud fra de to tilgange (træningsdata vs. realtidshentning på web):
Autoritets-publiceringsplatforme (LinkedIn, Medium, Substack): Hyppigt crawlet, høj domæneautoritet og hurtigt indekseret. LinkedIn-artikler er knyttet til rigtige professionelle profiler, hvilket giver dem et troværdighedssignal, som LLMs reagerer på. Mediums minimalistiske, semantiske struktur er meget LLM-læsbar. Substack egner sig til thought leadership og newsletter-lignende content.
Branchepublikationer og earned media: Nichesites med høj autoritet veægter uforholdsmæssigt tungt, når AI søger ekspertkilder inden for en specifik vertikal. Et mention på en respekteret brancheblog overgår bred, generel mediedækning for målrettede søgningerr. At blive fremhævet i "best of"-oversigter, nyhedsbreve, blogindlæg, kuraterede lister, er særligt vigtige, da disse formater er blandt dem, LLMs hyppigst citerer.
Anmeldelsesplatforme (G2, Capterra, Trustpilot): Flittigt citeret, når brugere beder AI om anbefalinger til redskaber. Disse platforme gives høj troværdighed, fordi de samler tredjeparts-brugeroplevelser snarere end brand-produceret content. Prioritér at få detaljerede, specifikke anmeldelser fra jeres kunder.
Reddit og Quora: Ifølge Semrush citeres Reddit mere end nogen anden enkelt kilde i LLM-svar. Quora er det hyppigst citerede website i Googles AI Overviews. Begge belønner specifikke, ekspertdrevne og velformaterede bidrag, ikke reklamepræget content.
YouTube: YouTube-citations i Large Language Models-svar er steget mærkbart gennem 2025, efterhånden som AI-systemer forbedrer sig til at udtrække fra transkriptioner, undertekster og beskrivelser. Optimér videotitler, beskrivelser og undertekster med de samme principper som for skriftligt content.
GitHub Discussions: For tekniske brands er GitHub community diskussioner en stærk og underudnyttet seeding kanal. At deltage i relevante tråde, besvare spørgsmål og bidrage med rettelser opbygger en troværdighed, som AI opfanger positivt.
Redaktionelle microsites: Et selvstændigt, redaktionelt struktureret microsite, bygget rundt om din branche, ikke blot dit produkt, kan have mere citations-troværdighed end et branded website. IKEAs "Life at Home" website er et godt eksempel: det publicerer original data om hjemmeliv og lykke, der kobler til brandet uden at være et produktkatalog. Strukturér det som en forholdsvis uafhængig publikation, inkludér forfatterbios, citér dine kilder og gør dine redaktionelle retningslinjer synlige.
Dit eget site (med teknisk AEO): Fundamentet. Selv om AI ikke altid citerer dit domæne direkte, styrker et velstruktureret website med domain autoritet dit brands entitetsrepræsentation og hentes hyppigt via RAG.
Content-formater, der giver citations
Formatet på content betyder ligeså meget som substansen. Visse strukturer er simpelthen lettere for AI at uddrage fra og citere.
"Best of"-lister er blandt de mest benyttede formater for LLM-citations. Men de skal være mere end en simpel rangeret liste. Gå i dybden, vær specifik, vær troværdig. Benyt samme formattering for alle entries på listen.
Egne produktanmeldelser med målbare resultater er citations-værdige, fordi de indeholder de tre ting, som AI stoler mest på: rigtig testning, gentagelig metode og specifikke citerbare konklusioner. Inkludér, hvor mange emner du testede, hvem der foretog testningen, hvornår det blev gennemført, og hvilke kriterier du anvendte.
FAQ-format content afspejler den præcise struktur af AI-forespørgsler. Spørgsmål-og-svar-formatet er i al væsentlighed forhåndsformateret til udtrækning af AI. Enhver central side på dit site bør inkludere en FAQ-sektion, der målretter de specifikke spørgsmål, brugerne stiller AI-redskaber.
Sammenligningsværktøjer trækkes konsekvent ind i beslutningsorienterede forespørgsler. Gå ud over funktionssammenligninger. Inkludér use-case-konklusioner ("bedst til X"), klare afvejninger og citations-klar formulering, der præcist fortæller AI, hvilken løsning der passer til hvilken brugertype.
Nummererede lister og trin-for-trin-guides er nemme for modeller at analysere og citere. En "Hvordan gør man..."-guide med nummererede trin er mere citations-venlig end flydende prosa, der dækker det samme emne.
Indlæg med klare takeaways giver citations, når de indtager en ægte, velunderbygget position. En kontrær brancheopfattelse eller en datadrevet forudsigelse, særligt fra en navngiven, kvalificeret forfatter, giver AI noget distinkt at referere til.
Navngivne ekspertudtalelser og E-E-A-T-signaler tilføjer troværdighed, som AI genkender. Inkludér identificerede forfattere med bios, direkte citater fra navngivne fagfolk og referencer til specifik forskning.
Cases med specifikke resultater. Jo mere specifik, jo mere citations-værdig. Kvantificerede resultater ("reducerede svartiden fra 4 timer til 22 minutter") giver AI udtrækbare og verificerbare fakta, den kan inkludere med tillid.
Redskaber, skabeloner og frameworks tiltrækker citations, fordi de løser specifikke problemer, som brugerne refererer til gentagne gange. Giv din ressource en beskrivende titel, der matcher, hvordan brugerne søger, inkludér en intro, der forklarer, hvem den er til og hvordan man bruger den, og tilføj FAQs eller use-case-eksempler, så AI forstår dens kontekst og værdi.
Sådan tracker du brand synlighed i AI-search
At måle LLM seeding-succes kræver et andet sæt redskaber end traditionel SEO-analyse. Kanalen er nyere, og signalerne er mindre standardiserede. Der er mange spillere som tilbyder AI search visibility tracking. Vi introducerer jer til nogle af dem i dette afsnit.
GSC-signalet: Stigende impressions, faldende kliks
En af de klareste tidlige indikatorer for LLM-indflydelse er et specifikt mønster i Google Search Console: impressions stiger, mens clicks falder. Det sker, fordi brugere ser dit brand nævnt i et AI-svar, noterer sig det mentalt og derefter søger direkte efter dig dage eller uger senere, og dermed omgår det organiske klik helt. Resultatet er faldende organiske click-through rates kombineret med stabile eller voksende branded søgninger og direkte trafik.
Sådan spotter du det: åbn Google Search Console og sammenlign impressions versus clicks over de seneste 3–6 måneder. Krydstjek derefter med Google Analytics. Hvis direkte trafik vokser, mens organiske clicks falder, påvirker LLMs sandsynligvis awareness. Det er et positivt signal, ikke et problem.
Manuel prompt-testning (gratis)
Den nemmeste metode: stil regelmæssigt AI search tools de spørgsmål, som du tror dine kunder stiller, og observér, om dit brand optræder i svarene. Brug en privat eller inkognito-browser for at undgå, at personalisering forvrænger resultaterne. Test på tværs af ChatGPT, Perplexity, Claude, Grok og Google AI Overviews. Det samme brand kan se citation rates, der spænder fra under 1 % på én platform til over 27 % på en anden, hvilket gør flerplatforms-testning interessant.
Byg en prompt bank med 20–30 repræsentative forespørgsler på tværs af forskellige funnel-stadier. Kør dem månedligt og dokumentér: hvilken LLM, den præcise prompt, om dit brand optrådte, hvor i svaret det figurerede (svar og/eller kilde), den stemning og framing det præsenteres med, og hvilke konkurrenter, der citeres ved siden af dig (svar eller kilder)
AI Monitoring software
- Otterly.ai (https://otterly.ai): Tracker AI-genererede citations og brand-mentions på tværs af ChatGPT, Perplexity og LLM's.
- Profound AI (https://www.tryprofound.com): Enterprise-platform; tracker LLM-søgevolumen, citation frequency og bot-trafik-analytics
- Semrush AI Visibility Toolkit (https://www.semrush.com/ai-seo/): Tracker brand performance, share of voice og sentiment på tværs af ChatGPT, Perplexity og Google AI Mode; inkluderer konkurrent-benchmarking
- PromptMonitor (https://www.promptmonitor.ai): Overvåger brand-mentions på tværs af LLM-platforme
Analytics-konfiguration
Konfigurér din webanalyse til at opfange AI-referred trafik korrekt. Mange platforme fejlattribuerer i dag LLM-trafik som "direct", hvilket betyder, at dine data sandsynligvis undervurderer AI-søgnings drevne besøg markant. Tilføj custom channel groupings, der opfanger trafik fra ChatGPT, Perplexity, Copilot og Gemini referral-domæner. Track denne trafik separat og sammenlign dens conversion rate med organiske og direkte kanaler.
De fem metrics, der betyder noget
Ud over placeringer skal du fokusere på disse AEO-specifikke KPI'er:
- Citation Frequency: Hvor ofte dit brand optræder i AI-svar for mål-prompts
- Brand Visibility Score: Procentdel af mål-prompts, hvor du modtager et mention
- AI Share of Voice: Dine citations som andel af de samlede citations i din kategori
- Sentiment Score: Hvordan AI framer dit brand (positivt, neutralt, negativt)
- LLM Conversion Rate: Omsætning eller leads tilskrevet AI-referred trafik
Almindelige faldgruber og realistiske forventninger
Tidsperspektivitet kan være længere end for SEO, men også meget kortere. Content optimeret til træningsdata kan tage adskillige måneder i forhold til at påvirke en models parametriske viden. Men når LLM's benytter relatids websøgninger kan du opnå en meget hurtig effekt. Planlæg en 3–6 måneders horisont, inden du forventer konsistente citation-ændringer for træningsbaserede modeller, nogle gange endnu længere. LLM seeding minder mere om brand-building og thought leadership end performance marketing. Det akkumulerer langsomt, derefter accelererer det.
Du påvirker, men kontrollerer ikke. AI-svar er probabilistiske. Der er under 1 ud af 100 chancer for, at ChatGPT producerer den samme liste af brands i to svar på identiske prompts. Du kan dramatisk øge sandsynligheden for at blive citeret; du kan ikke garantere det.
Gennemsigtighed i træningsdata er begrænset. Det er ikke altid klart, hvilke kilder en given model vægter højest. LLM seeding skal baseres på strategiske antagelser, såsom at troværdighed, konsistens, dybde og autoritative tredjeparts-mentions øger citations-sandsynlighed, snarere end præcis reverse engineering af en uigennemsigtig proces, omend det også giver hints om vejen til synlighed.
Attribution er svær. Zero-click AI-mentions opbygger brand awareness uden at generere målbar webtrafik. Det er reel værdi, men den vil ikke fremgå klart i din analytics. Proxy-metrics som stigninger i branded søgevolumen, vækst i direkte trafik og kvaliteten af sales-qualified leads fra AI-søgnings trafik hjælper med at lukke attribution-hullet.
Manipulation betaler sig ikke. At publicere fabrikerede anmeldelser, falske statistikker eller på andre måder at forsøge at manipulere AI-output med vildledende content har tendens til at slå tilbage, efterhånden som modellerne forbedres til at opdage manipulation. Den bæredygtige strategi som er præcis, hjælpsom, velstruktureret information på tværs af autoritative kilder, er i øvrigt også den etiske.
Fra AI-citations til omsætning
At blive citeret af AI er intet værd, hvis oplevelsen slutter der. Den høje konverterende natur af AI-referred trafik skyldes præcist, at disse besøgende ankommer forhåndskvalificerede. Men du skal stadig fange dem, når de lander. Det er her, at en chat-løsning med ekspertise i konverting, som Weply, kan være afgørende.
Over 13 måneder af data leverede LLM-refereret trafik en konverteringsrate på ca. 18 %. Højere end nogen anden digital trafik-kanal, inklusiv paid search, SEO og direct.
Den praktiske implikation: når AI-search trafik lander på dit site, er de mere tilbøjelige end nogen anden form for trafik, at evaluere et køb eller på anden måde seriøst overveje din løsning. Sørg for, at landingssider afspejler den kontekst, de kom fra. Brug kontekstuelle CTAs og chat, og undgå at behandle dem som kold trafik, der har brug for omfattende viden om din kategori. LLM trafik leverer generelt høj-intent besøgende. Chat på jeres hjemmeside fanger deres intent, inden den forsvinder.
FAQs om LLM Seeding
Hvor lang tid tager LLM seeding om at vise resultater? For træningsdata-baserede modeller som ChatGPT og Claude skal du forvente 3–6 måneder, inden content konsekvent påvirker citations. På webbaserede søgninger som Perplexity og andre LLM's foretager kan dereagere på nyt content inden for dage.
Er LLM seeding det samme som SEO eller AEO? Hverken eller, omend de er beslægtede. LLM seeding er en specifik taktik, der indgår i AEO (Answer Engine Optimization), som i sig selv er en bredere disciplin. SEO optimerer mod kliks ved gode placeringer i søgemaskiner, oftest Google. AEO optimerer til citations og autoritet på tværs af alle answer surfaces: stemmesøgning, featured snippets, knowledge panels og AI-redskaber. LLM seeding er AEOs mest vigtige taktikker: den fokuserer specifikt på at påvirke, hvad large language models ved og husker om dit brand, via bevidst content-placering i de kilder, AI lærer af. Næsten 90 % af ChatGPT-citations stammer fra sider, der rangerer på position 21 eller lavere i Google, hvilket illustrerer, hvorfor LLM seeding kræver sin egen logik, adskilt fra, men komplementær til, traditionel SEO.
Virker LLM seeding på samme måde på tværs af ChatGPT, Claude og Perplexity? Nej, og denne distinktion er vigtig. ChatGPT og Claude baserer sig i højere grad på parametrisk (trænings-)viden og er sværere at påvirke i realtid. Perplexity er primært en RAG-baseret motor, der henter frisk content under hvert enkelt opslag, og er dermed mere responsiv over for aktuelt, velstruktureret content. Google AI Overviews blander begge tilgange. En diversificeret strategi, der inkluderer konsistent webtilstedeværelse plus struktureret, crawlbart content, øger citations-sandsynligheden på tværs af alle platforme.
Kan små virksomheder konkurrere med store brands om AI-citations? Ja, særligt i nichevertikaler. Konsistens vejer tungere end budget. En lille virksomhed, der publicerer specifikke, velstrukturerede svar på hyppige spørgsmål, optjener ægte kundeanmeldelser, og deltager autentisk i community-forums, kan overperforme en større konkurrent, der publicerer generisk content. Identificér de specifikke, long-tail prompts, dine kunder stiller AI, og ej disse frem for at konkurrere på brede, høj-volume spørgsmål.
Hvordan korrigerer jeg unøjagtig information, som et AI-search tool spreder om mit brand? Publicér præcist, velkildet content på tværs af velansete platforme for at etablere den korrekte fortælling. Jo mere konsekvent troværdige kilder afspejler præcis information, jo hurtigere opdaterer AI-systemer. For kritiske korrektioner skal du prioritere Wikipedia (hvis relevant), store anmeldelsesplatforme og earned media-dækning. Disse vejer tungest i både træningsdata og realtidshentning fra web.
Er LLM seeding etisk?Ja, når det fokuserer på at gøre sandfærdig, hjælpsom brandinformation tilgængelig. Målet er at sikre, at AI kan finde og verificere præcis information om dit brand og produkt. Ikke at bedrage brugere eller manipulere AI med falske påstande. At skabe nyttigt content, få autentiske anmeldelser og opbygge reel tredjeparts-troværdighed er de taktikker, der virker. Og de er heldigvis fuldt ud etiske.